I Want to Look at Something Beautiful
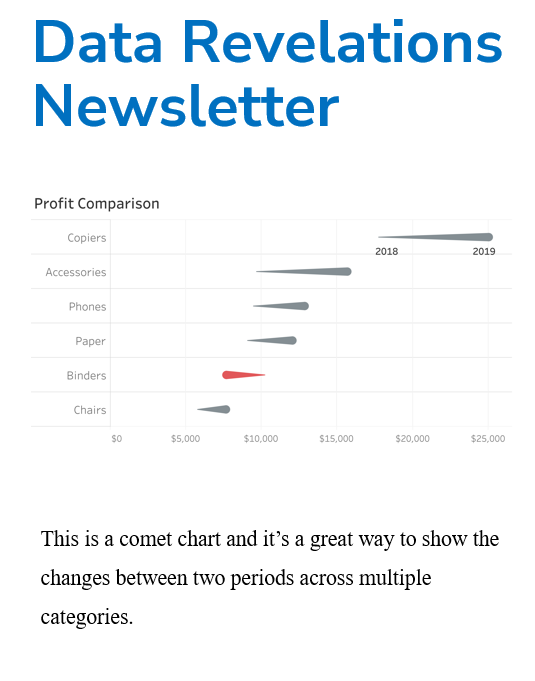
Some thoughts on functionality, beauty, crown molding, and lollipop charts Overview I’ve been writing a book about business dashboards with Jeffrey Shaffer and Andy Cotgreave and we’ve conducted screen-sharing sessions with dozens of people and reviewed scores of dashboards. We had a particularly enjoyable jam session with Tableau Zen Master Mark Jackson last week. When [...]