Likert Scale Questions the Zvinca Way
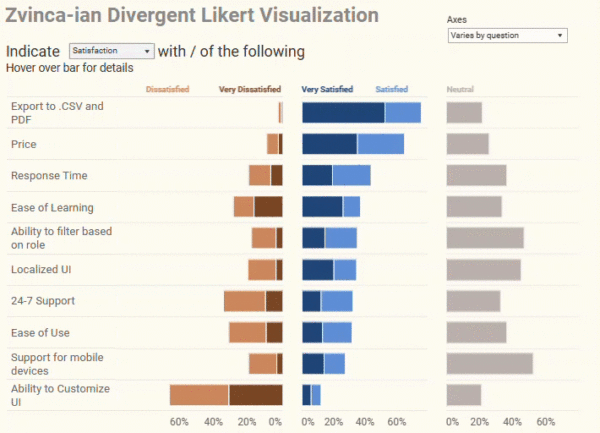
Overview Although I was on vacation in April of 2023, I did see this twitter post. Daniel Zvinca’s response knocked my socks off. Here’s the post from Cole Knaflic. And here was Daniel’s response. “Goodness, yes” I thought. This addresses the shortcomings of what I’ll call the “inside out” approach for displaying Likert scale survey [...]