By Steve Wexler, January 15, 2017
Overview
Before going any further this post assumes you’ve gotten your data “just so”; that is, you’ve reshaped your data and have the responses in both text and numeric form.
If you’re not sure what this means, please review this post.
Taking inventory by finding the universe of all questions and all responses
Anyone who has attended one of my survey data classes or has watched my 2014 Tableau Conference presentation knows the first thing I like to do is assemble a demographics dashboard so I know who took the survey.
The second thing I do arose a few months ago when I had a “why didn’t I do this before” moment with respect to getting a good handle on questions, responses, and seeing if there was anything that was poorly coded.
Here’s how it works.
Note that I’m using the same sample data set that I use for my classes.
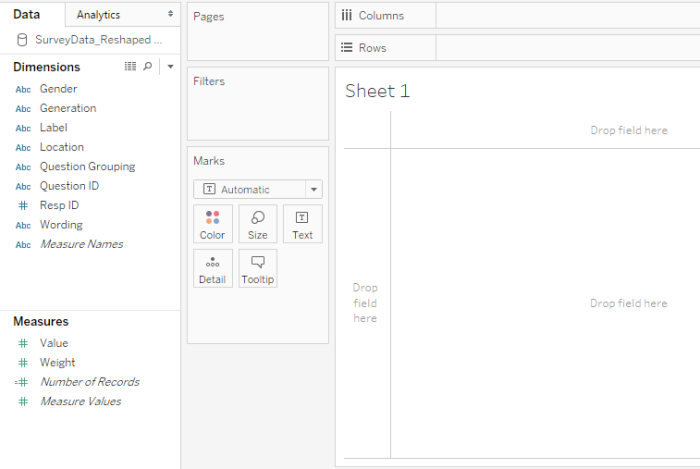
Figure 1 — Screen shot after just having connected to the data.
- Drag Question Grouping onto rows, followed by Wording, and then Question ID, as shown below.
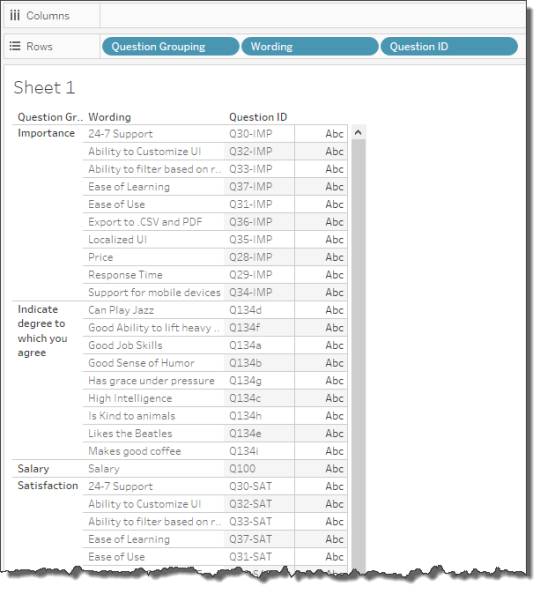
Figure 2 — About half-way through taking inventory.
- Right-click the measure called Value and select Duplicate.
- Rename the newly-created field Value (discrete).
- Drag the measure into the Dimensions area. This will make Tableau treat the field as something that is by default discrete.

Figure 3 — Turning the measure into a discrete dimension
- Drag new newly-created dimension to Rows.
- Drag Labels to Rows. Your screen should look like the one shown below.
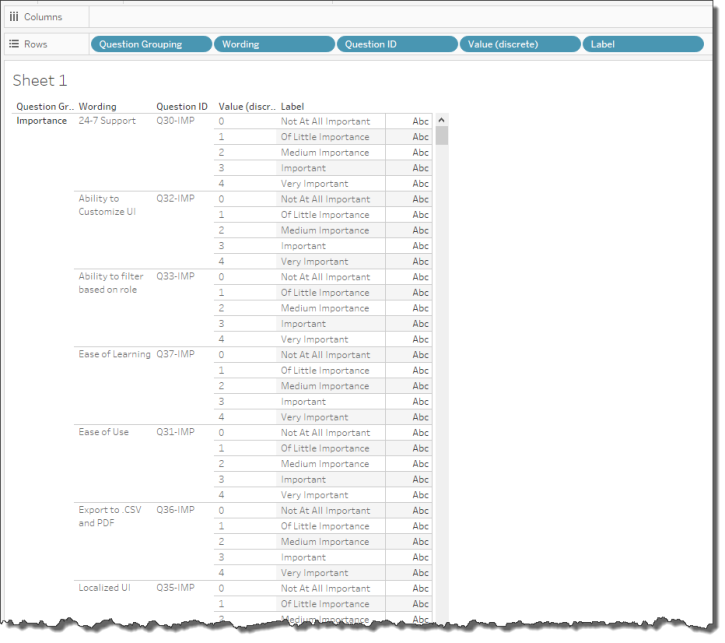
Figure 4 — All the questions and all the responses, all on one sheet.
So, just what do we have here?
You can see from the portion of the screen that you have a bunch of questions about “Importance” and can also see that the possible values go from 0 to 4 where 0 maps to “Not at all important”, 1 maps to “Of Little Importance”, etc.
At this point you should be looking for any stray values, say a value of 5.
If you scroll down a little bit (Figure 5) you’ll see a question grouping called “Indicate the degree to which you agree” where you again have values of 0 through 4 but this time 0 maps to “Not at all”, 1 maps to “Small degree”, etc.
We should be pleased as it appears that our Likert questions consistently go from 0 through 4. This means we won’t have to craft multiple sets of calculated fields to deal with different numeric scales (not that having to do that would be a big deal).
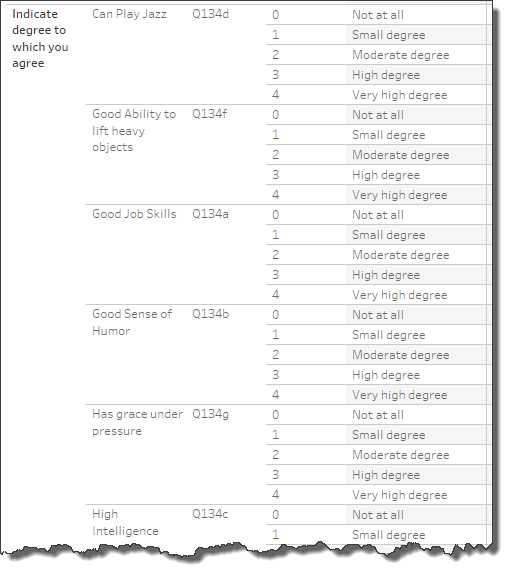
Figure 5 — Next set of questions.
At this point it might be useful to add a filter so you can focus on only certain question groups. You can do this by filtering by Question Grouping as shown below.
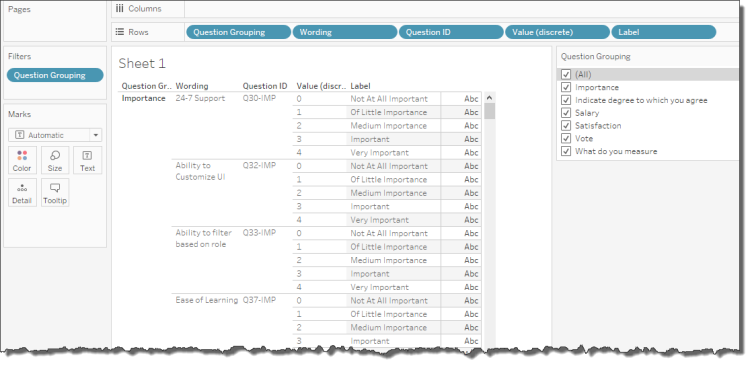
Figure 6 — Adding a filter makes it easier to focus on specific question groupings
Spotting questions that have coding errors
In case you’re wondering what a coding error looks like, see what happens if we just focus on the “What do you measure” questions, as shown below.
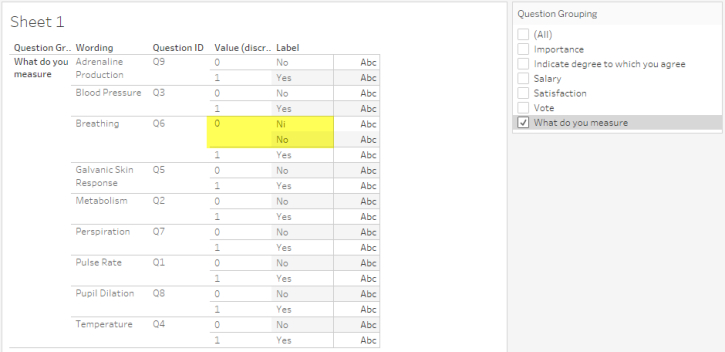
Figure 7 — An example of a mis-coded check-all-that-apply question
So, for all of the check-all-that-apply questions the universe of possible values is 0 and 1. And with the exception of Question Q6 (Breathing), 0 maps to “No” and 1 maps to “Yes.”
The mis-coding of “Ni” instead of “No” will only present a problem if our calculated field for determining the percentage of people that checked an item were to use Labels instead of Values. My preferred formula for this type of calculation is this:
SUM([Value]) / SUM([Number of Records)])
Because we’re using [Value] instead of [Label], the miscoding for this example won’t cause a problem.
Conclusion
Creating a giant text table that maps all Question Groupings, Question IDs, Labels, and Values on a single sheet allows us to quickly take an inventory of all questions and possible responses. This in turn allows us to see if questions are coded consistently (e.g., do all the Likert Scale questions use the same scale) and to see if there are any coding errors.
I just wish I had started doing this years ago.